EIR-OPS-027: Reboot Fault Analysis
Warning
TC authentication is disabled at boot to reduce the risk of loosing communication with the spacecraft. Therefore, if not already enabled as part of the EIR-OPS-025: Safe Mode Entered procedure, TC authentication is now disabled. The Operator should consider following the EIR-OPS-009: Enable TC Authentication procedure ASAP to re-enable TC authentication to prevent replay attacks.
Objective
To determine why a reboot has occurred.
Introduction
Using this procedure, the Operator will analyse downlinked data to determine the most likely reason for an OBC reboot.
Note
The analysis to be carried out by the team is very dependent on the findings as well as what data was successfully downlinked. Therefore, rather than a strict set of instructions, this procedure instead provides information to help guide the Operator in their analyses. Also note that in addition to any data downlinked by the UCD GS, data obtained via the amateur radio community may also be used to support the analyses.
Procedure
Note
The Operator is directed here from a number of different procedures. To ensure it is useful in all scenarios, the Operator is advised below to perform all the relevant checks. However, in many cases, many of these checks have already been performed. In this case, the Operator can just skip ahead to the next step/consideration.
A.1.
In the downlinked HK data, find where
core.OBT.Uptimeresets to ~0.Take note of the log time of the data just before this
Uptimereset as the spacecraft’s on-board time (OBT) when the reboot occurred.
A.2.
Around the OBT of the reboot, search the downlinked Event log for the ‘EPSInitialised’ event, which is raised when a full spacecraft power-cycle has occurred.
A.3.
If the ‘EPSInitialised’ event is NOT observed in the Event log, skip to the ‘OBC RESET’ section below.
Else, if the event is observed in the Event log, the Operator should now proceed to the ‘FULL SC POWER-CYCLE’ section.
FULL SC POWER-CYCLE
A.4.
It is highly unlikely that the Operator would not know about a command sent to power-cycle the spacecraft. However, the possibility should still be ruled out. Therefore, using the MCS/GS logs verify that the
Invoke:platform.EPS.cycleBusTC was not sent to the spacecraft around the OBT of the reboot.
A.5.
Using the downlinked HK data, assess if the
platform.BAT.batteryVoltage[2]orplatform.EPS.busVoltage[0]parameters decreased to ~6.144V in the time leading up to the reboot.If this is observed, the Operator should now proceed to EIR-OPS-026: Low Battery Fault Analysis as this likely indicates that the EPS’s low voltage protection function caused the spacecraft to temporarily power OFF.
Else, proceed to the next step.
A.6.
Around the OBT of the reboot, search the downlinked Event log for the ‘NoTCReceived’ event, which is raised when no TCs are received from the UCD GS in N days, where N =
mission.ModeManager.NoTCWatchdogTimeout(by default, N = 3 days).Following this event, the spacecraft automatically invokes the
platform.EPS.cycleBusaction to power-cycle all of the EPS power buses. Therefore, if this event is observed in the Event log around the OBT of the reboot, the NO TC watchdog was the cause of the reboot.
A.7.
Using the downlinked HK data, assess whether an increase in the
platform.EPS.autoResetCount,platform.EPS.brownOutResetCountand/orplatform.EPS.WatchdogResetCountwas observed at the time of the reboot.If an increase in any of these three counters is observed, an automatically triggered EPS reset (i.e. triggered by some functionality in the EPS firmware and/or hardware) led to the power-cycle/reboot.
The next step may identify the cause of such a reset.
A.8.
Using the downlinked HK and/or TED data, assess any of the parameters associated with the EPS. More specifically, look at the parameter values as well as their associated
cdh.telemetry.DataPool.IsValidparameters (related to the cached datapool parameter value), to determine if the OBC may have experienced any I2C communication issues with the EPS ~minutes prior to the reboot. Figure 1 shows the expected drop to zero in EPS data if an I2C error occurs. Check if:The parameter values are valid/sensible.
The parameter values are updating between readings.
The cached datapool parameter values are valid (i.e.
IsValid= 1).
If issues are identified with the logged parameter values ~4 minutes prior to the reboot, the EPS watchdog may have led to the power-cycle/reboot as a result of I2C read/write errors between the OBC and EPS. This should be coupled with an increasee in the
platform.EPS.WatchdogResetCountparameter.
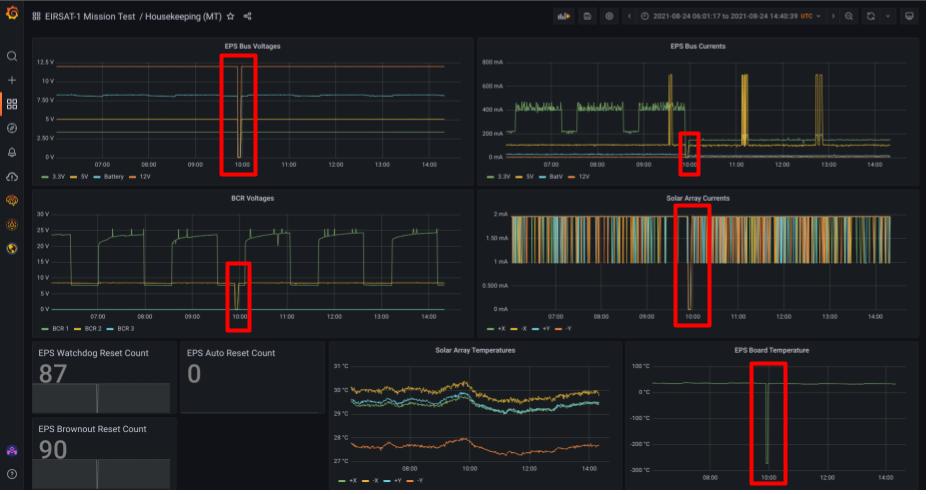
Figure 1 - EPS data from the HK packet (from the EQM Mission Test) showing I2C error between OBC and EPS, as all EPS data drops to zeros.
A.9.
If none of the above situations are likely, the Operator should perform a general assessment of the all EPS and battery related parameters from any downlinked HK, TED and PASCAL data to determine if any anomalous behavior was observed around the OBT of the reboot that may have contributed to or been evidence of the issue that led to the spacecraft power-cycle/reboot.
Tip
In addition to the instantaneous values of each parameter, check how the values changed with time. Use the Grafana Mission Monitoring System (MMS) to help with this.
OBC RESET
A.10.
It is highly unlikely that the Operator would not know about a command sent to perform an OBC reset. However, the possibility should still be ruled out. Therefore, using the MCS/GS logs verify that the
Invoke:platform.OBC.obc.resetTC was not sent to the spacecraft around the OBT of the reboot.
A.11.
Only one on-board software FDIR check is implemented to trigger an OBC reset. This is the CMCAliveCheck FDIR functionality, which triggers a reset in the event that the OBC is unable to I2C communicate with the CMC for a prolonged, ~2.5-hour period.
To determine whether this functionality has been triggered, the Operators should review the downlinked data for evidence of I2C read/write errors between the OBC and CMC in the ~hours prior to the reboot. In this case, similar behaviour to that shown in Step 8/Figure 1 should be observed, where all CMC data in the HK, and other, packets falls to zeros.
OBC-to-CMC I2C errors will also result in many events. Therefore, if this scenario has occurred, the
core.EventDispatcher.eventCount(in TM the Beacon data) andcdh.logging.EventLogger.absRowsLoggedparameters should have risen drastically (e.g. by hundreds to thousands) compared to the parameter values before the anomaly. The downlinked Event log should also be filled with error events.
A.12.
Excluding a commanded reset and the CMCAliveCheck FDIR functionality, an OBC reset occurs due to a software fault or a Single-Event Upset (SEU). As it is not possible to confirm an SEU, analysis can only be performed to determine if the former was likely the cause and so, the following should now be considered:
Were any commands being sent to the satellite at the time of reboot - by the UCD GS or another (was TC authentication enabled?)?
Were any specific operations expected to occur at the time of the reboot? e.g. something invoked by the TimeAction component?
Was the OBC/OBSW performing any relatively NEW operations at the time of the reboot? ‘New’ meaning an Operation that has either not run before and/or an operation that has not run for this duration before.
Has a similar reboot occurred before? Is there any reason to believe this related to previous OBC resets (i.e. is it a time related bug)?
Does the downlinked data suggest that at the time of the reboot the OBC/OBSW was experiencing any other faults in operation?
END OF PROCEDURE